
vLLM 多机多卡推理部署DeepSeek-R1-Qwen-32B
1. 服务器准备
本文两台服务器规格完全一致:
- Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz 64核处理器
- 128G 内存
- Nvidia RTX 4070Ti 12G 显卡 * 2
确保服务器有足够存储空间
给
/根目录预留足够大的空间虽然一些组件(如docker)可修改存储位置,但为了避免折腾,
务必给/根目录保留足够的空间多机多卡推理需要将模型分割,该操作会占用磁盘空间,请确保
磁盘可用空间大于模型大小安装好显卡驱动和CUDA
可以直接在英伟达官网下载
CUDA Toolkit,CUDA Toolkit Archive | NVIDIA Developer,按照教程正常安装即可
2. 下载模型
可前往 huggingface.co 下载,如果无法访问外网,可以从首页 · 魔搭社区 下载
本文以 DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf 模型为例
将模型下载好,分别放入两台服务器的目录中,注:两台服务器的模型存放目录路径务必保持一致
3. 安装 Docker,如果已安装Docker可跳过该章节
3.1. 删除旧数据
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done
【一键安装】
可以使用以下命令一键安装Docker,使用后可跳过3.x章节
bash <(curl -sSL https://raw.githubusercontent.com/SuperManito/LinuxMirrors/main/DockerInstallation.sh)
3.2. 添加 Docker 仓库
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
[可选]添加阿里云 Docker 安装仓库curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update
3.3. 安装最新版 Docker-CE
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 设置开启运行
sudo systemctl enable docker
3.4. [可选]设置国内 Docker 镜像源
sudo mkdir -p /etc/docker
# 需寻找最新可用仓库
sudo tee /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.xuanyuan.me"
],
"features": {
"buildkit": true,
"containerd-snapshotter": true
}
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
4. 安装 vLLM 集群运行环境
4.1. 拉取 vLLM Docker 镜像
sudo docker pull vllm/vllm-openai
4.2. 下载启动集群脚本 run_cluster.sh
脚本地址
vllm/examples/online_serving/run_cluster.sh at main · vllm-project/vllm
可以使用wget命令下载,如果服务器网络不支持,可以本地科学上网下载后上传到服务器
wget https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh
下载后的文件用于 5. 启动 vLLM 集群 章节
4.3. 获取 NVIDIA Container Toolkit 安装源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sudo sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
4.3.1. 如果
nvidia.github.io问不了,可使用国内源
参考[NVIDIA Container 运行时库 - USTC Mirror Help](https://mirrors.ustc.edu.cn/help/libnvidia-container.html)curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sudo sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list4.3.2. 如果
gpgkey也无法下载的话,可以本地下载好,传到服务器上,然后改成执行以下命令sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg /gpgkey路径 curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sudo sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
4.4. 执行安装 NVIDIA Container Toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
4.5. 配置 Docker GPU 运行环境
sudo nvidia-ctk runtime configure --runtime=docker
# 重启docker
sudo systemctl restart docker
5. 启动 vLLM 集群
5.1. 启动 head 主节点
# 可以配合nohup后台运行
# 为何指定版本,可下拉看【常见问题】章节
sudo bash run_cluster.sh \
vllm/vllm-openai:v0.7.3 \
主节点IP \
--head \
/模型目录 \
-e VLLM_HOST_IP=当前机器的ip
5.2. 启动 worker 从节点
# 可以配合nohup后台运行
# 为何指定版本,可下拉看【常见问题】章节
sudo bash run_cluster.sh \
vllm/vllm-openai:v0.7.3 \
主节点IP \
--worker \
/模型目录 \
-e VLLM_HOST_IP=当前机器的ip
5.3. 进入 head 容器内启动推理服务
# 使用docker ps命令查找容器id
sudo docker ps
# 进入容器内部
sudo docker exec -it 容器ID bash
## 启动推理服务
# 容器内模型目录固定为 /root/.cache/huggingface/ 开头,该目录指向为 run_cluster.sh 参数中配置的映射的模型目录
vllm serve /root/.cache/huggingface/gguf/DeepSeek-R1-Distill-Qwen-32B-Q3_K_L.gguf \
# gguf 量化模型建议使用官方原生的 tokenizer
--tokenizer /root/.cache/huggingface/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
# 模型名称,用于接口中指定模型
--served-model-name DeepSeek-Qwen-32B-Q3-K-L \
# 暴露的 api 端口
--port 8000 \
# 占用的最大显卡内存比例, 0.9 则为 90%
--gpu-memory-utilization 0.90 \
# 最大模型上下文长度,
--max-model-len=16384 \
# 此处填单台服务器的显卡数量,本文单台服务器有 2 张显卡
--tensor-parallel-size 2 \
# 此处填服务器数量,本为为 2 台服务器
--pipeline-parallel-size 2
6. 常见问题
6.1. 报错:RuntimeError: Failed to infer device type
该报错在vllm v0.7.2 中出现,升级 docker 镜像到vllm v0.7.3或之后的版本即可
6.2. 报错:Gloo connectFullMesh failed
如下图,使用 ifconfig 命令列出服务器网卡,找到用于内网通讯的网卡名,比如我这里的名称为ens3
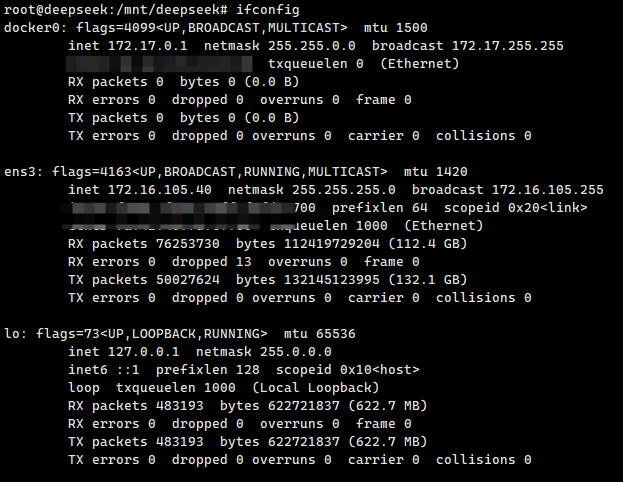
修改启动 vLLM 集群的命令,注: head 节点和 worker 节点的启动命令都需要修改!
# 启动主节点
sudo bash run_cluster.sh \
vllm/vllm-openai \
主节点IP \
--head \
/模型目录 \
-e VLLM_HOST_IP=当前机器的ip \
# 增加下面这一行,指定网卡名称
-e GLOO_SOCKET_IFNAME=ens3
## 启动从节点
sudo bash run_cluster.sh \
vllm/vllm-openai \
主节点IP \
--worker \
/模型目录 \
-e VLLM_HOST_IP=当前机器的ip
# 增加下面这一行,指定网卡名称
-e GLOO_SOCKET_IFNAME=ens3